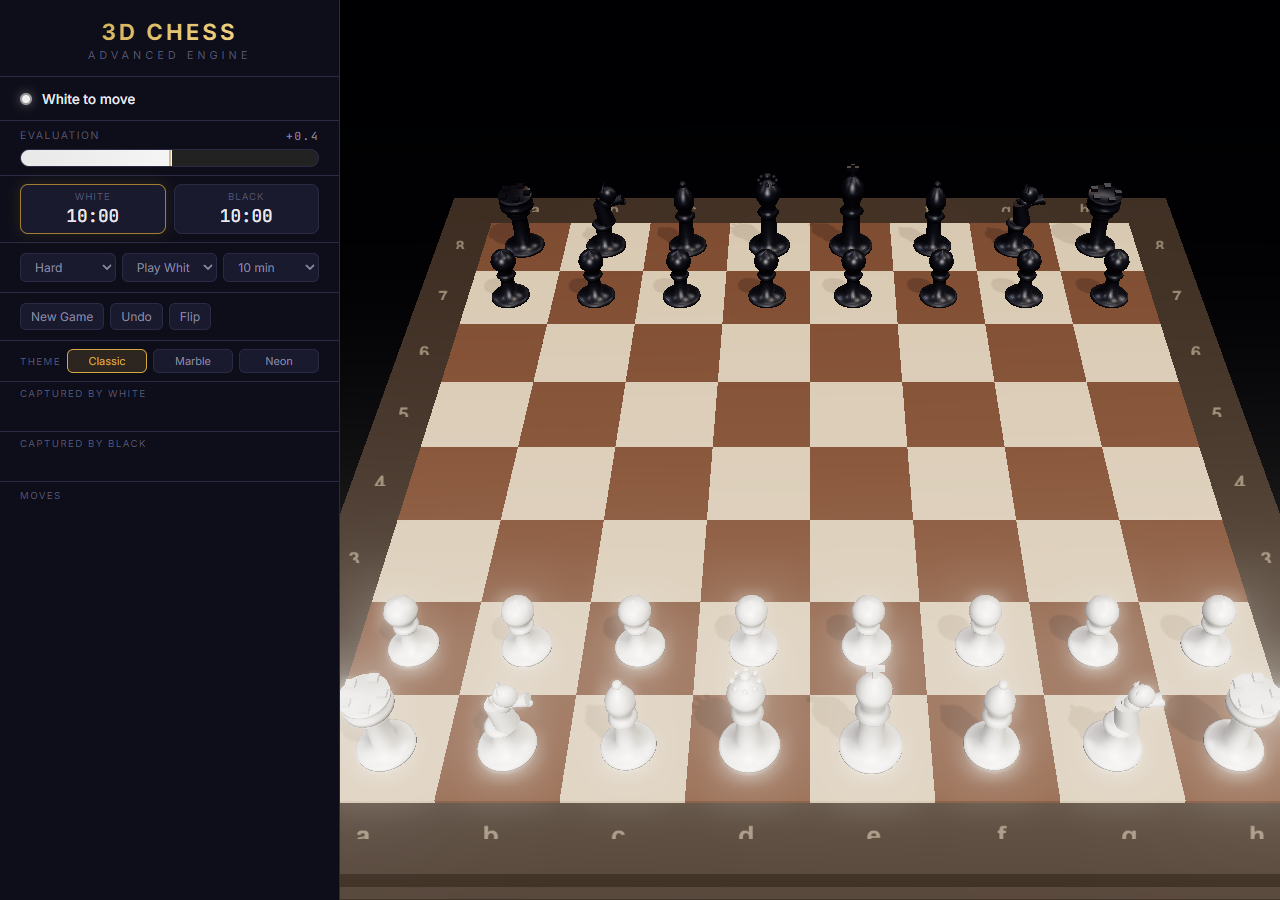
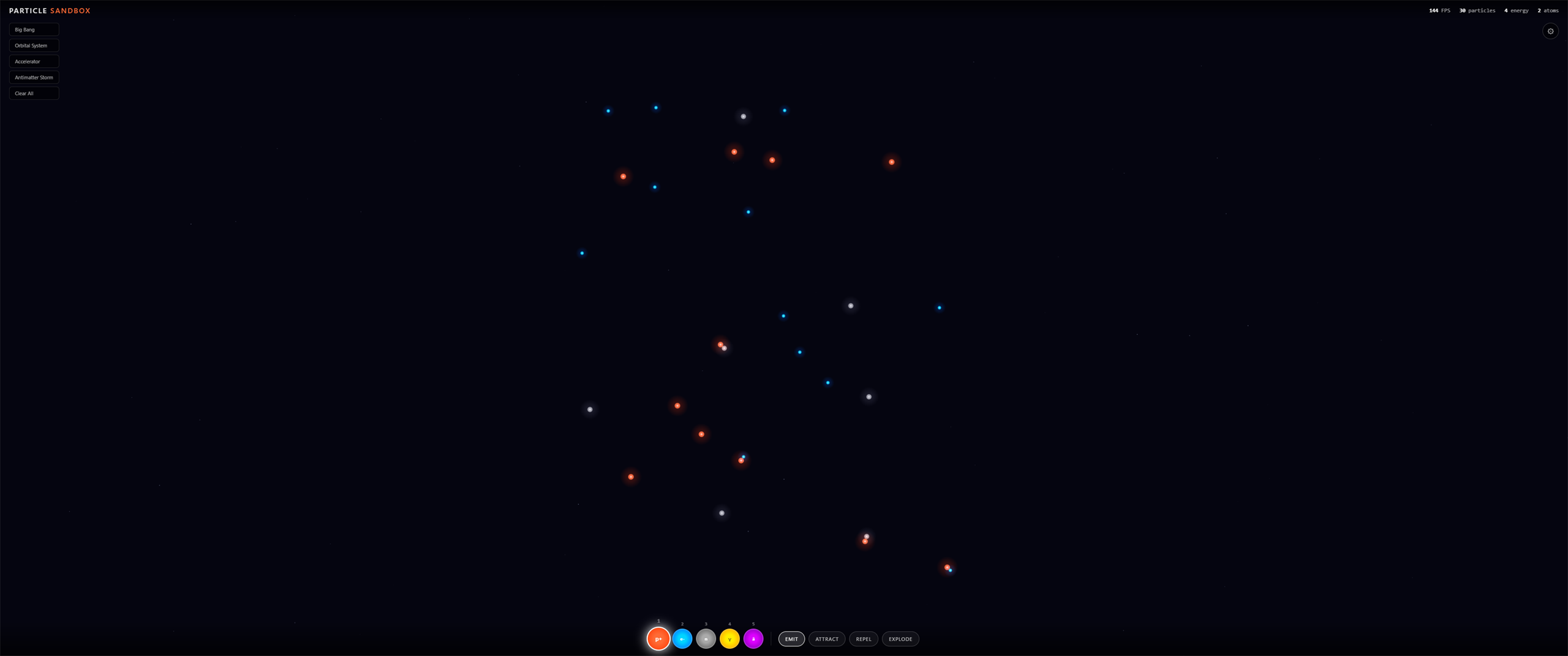
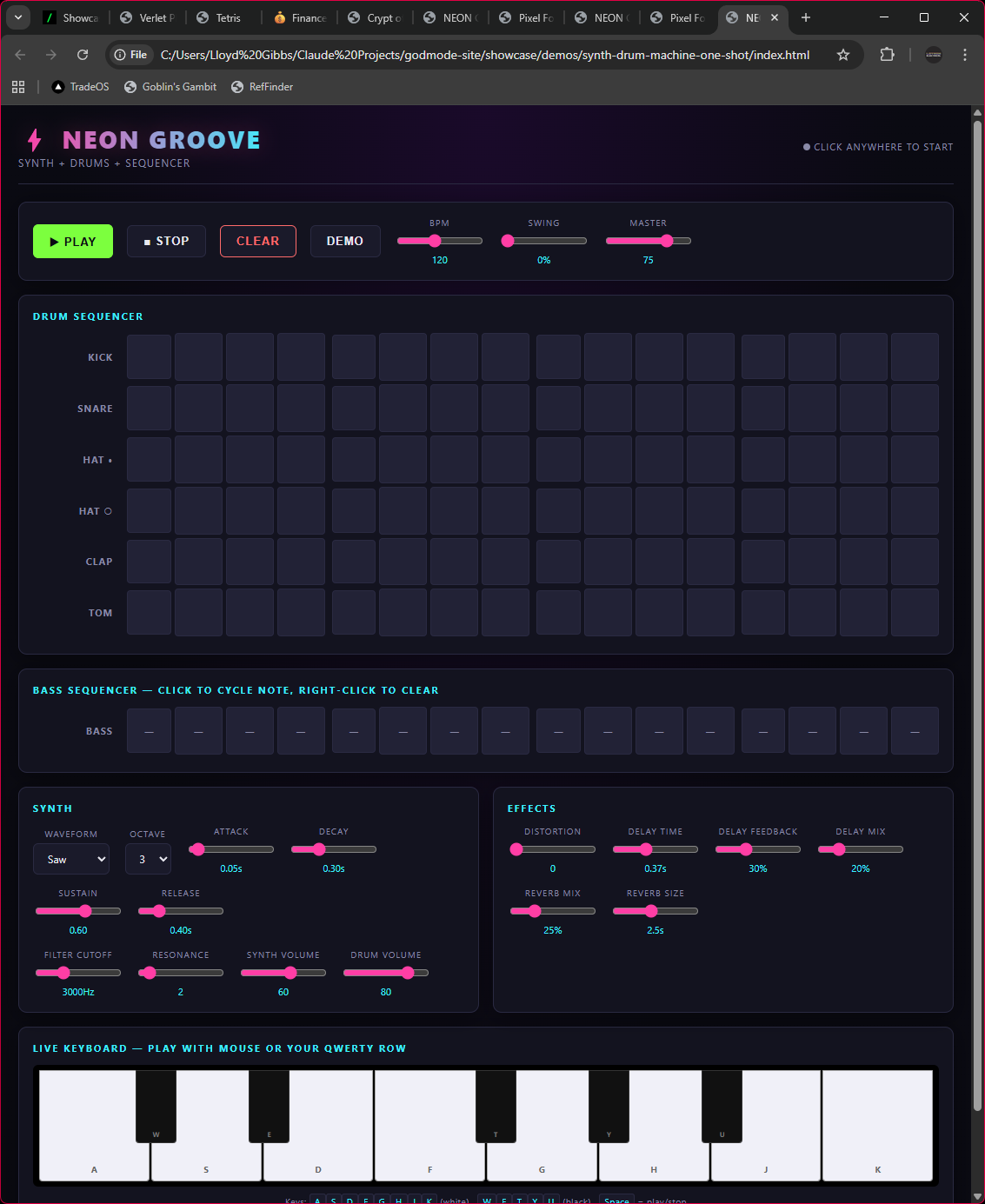
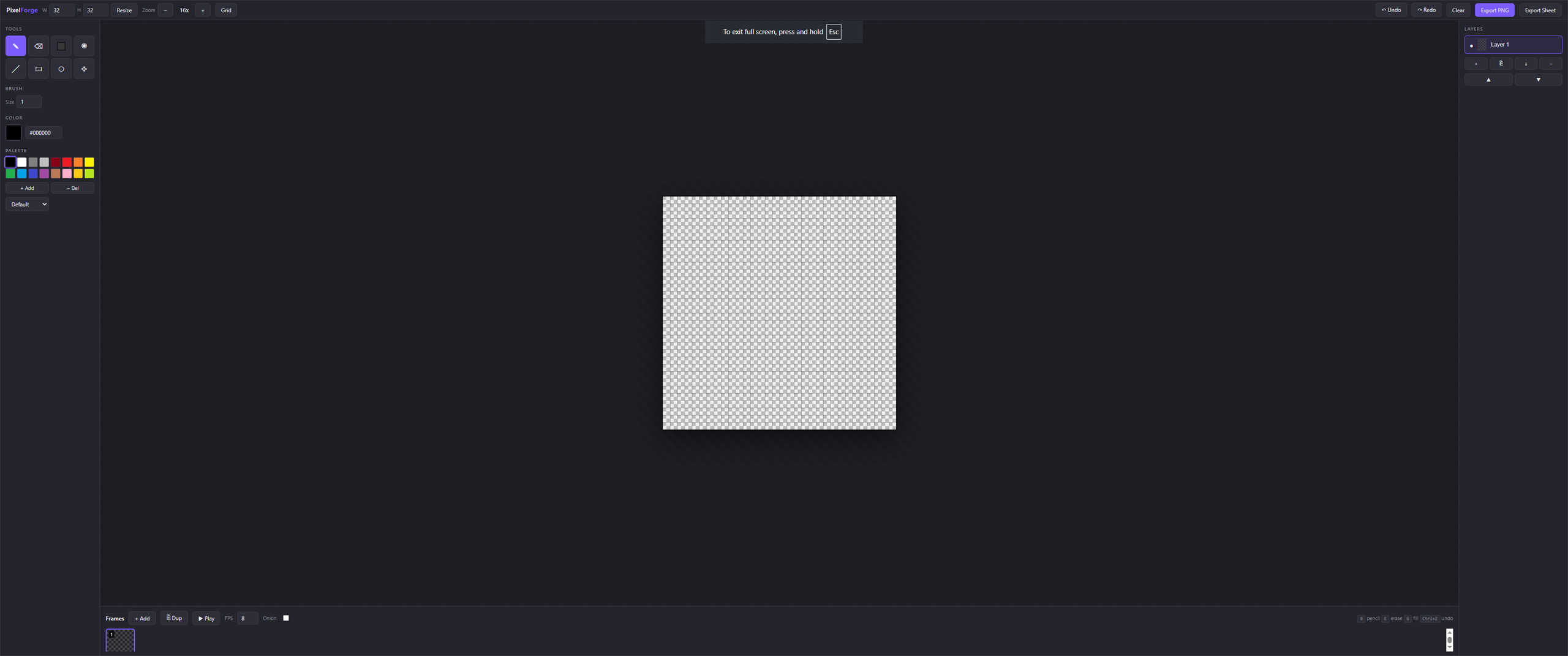
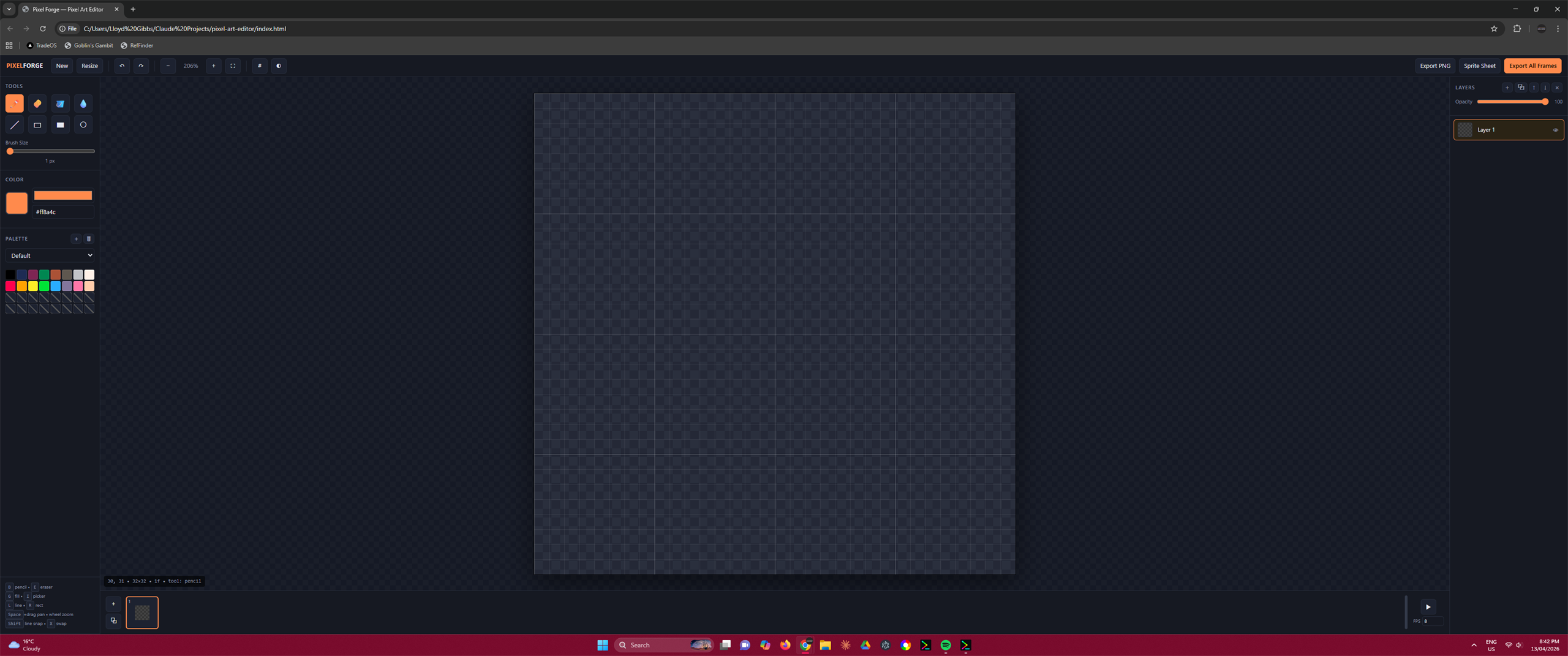
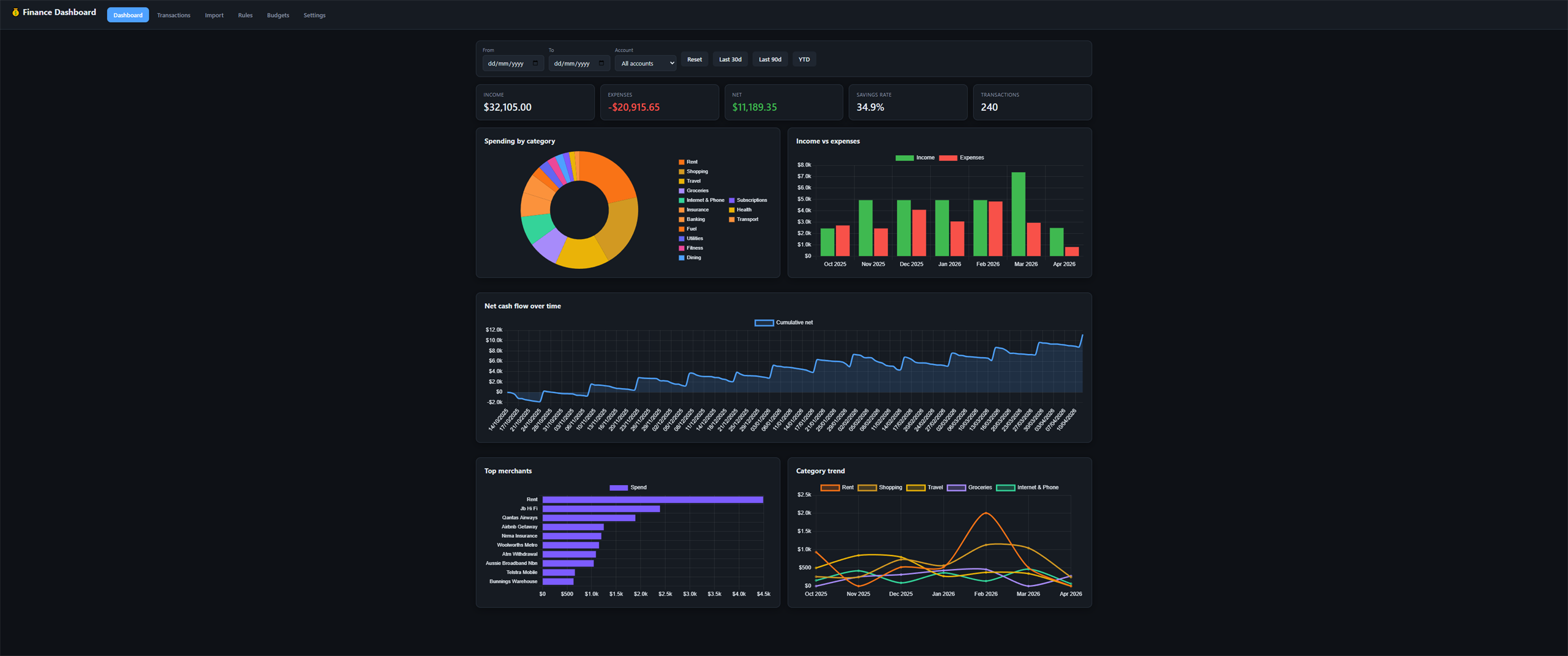
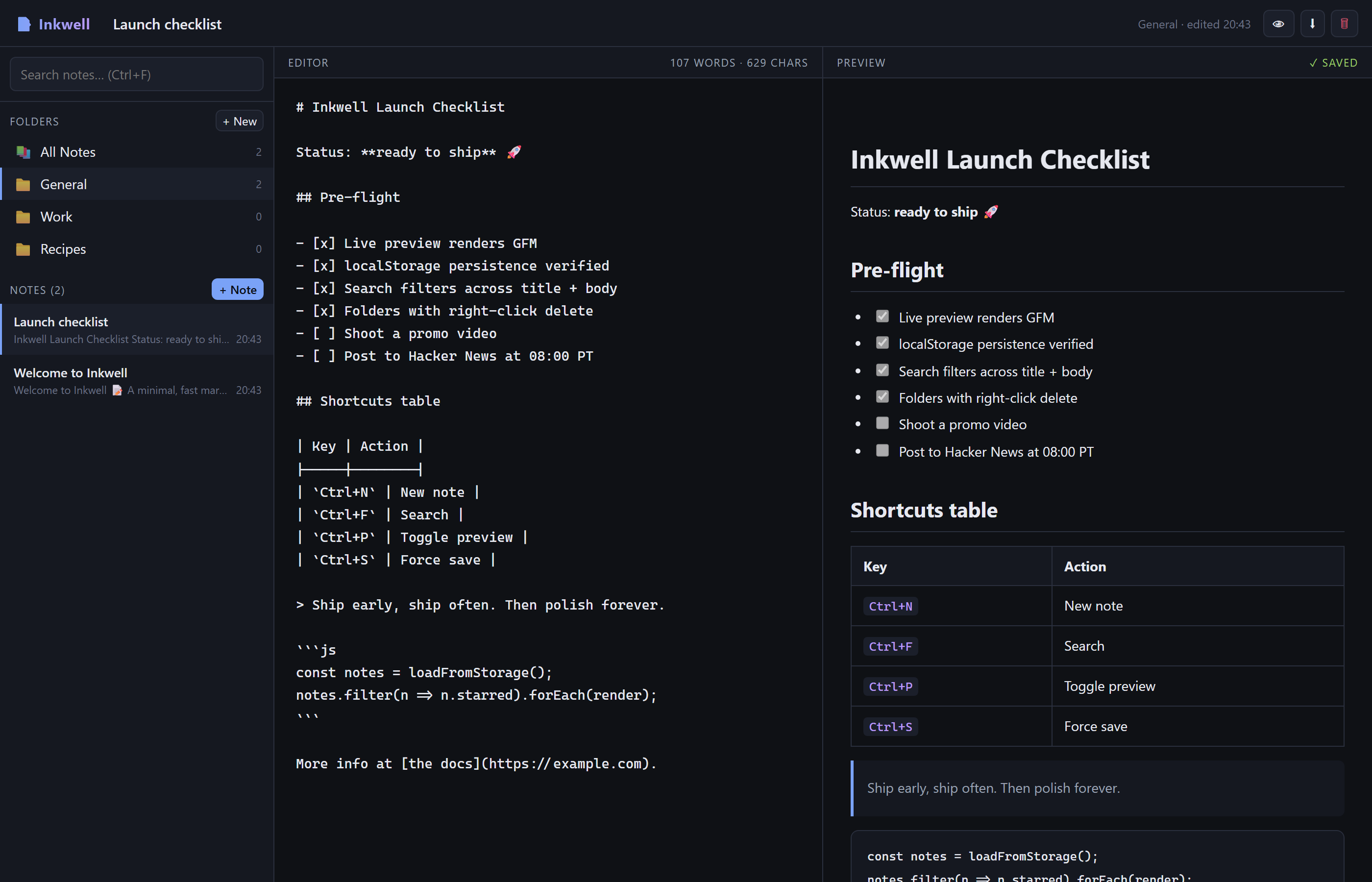
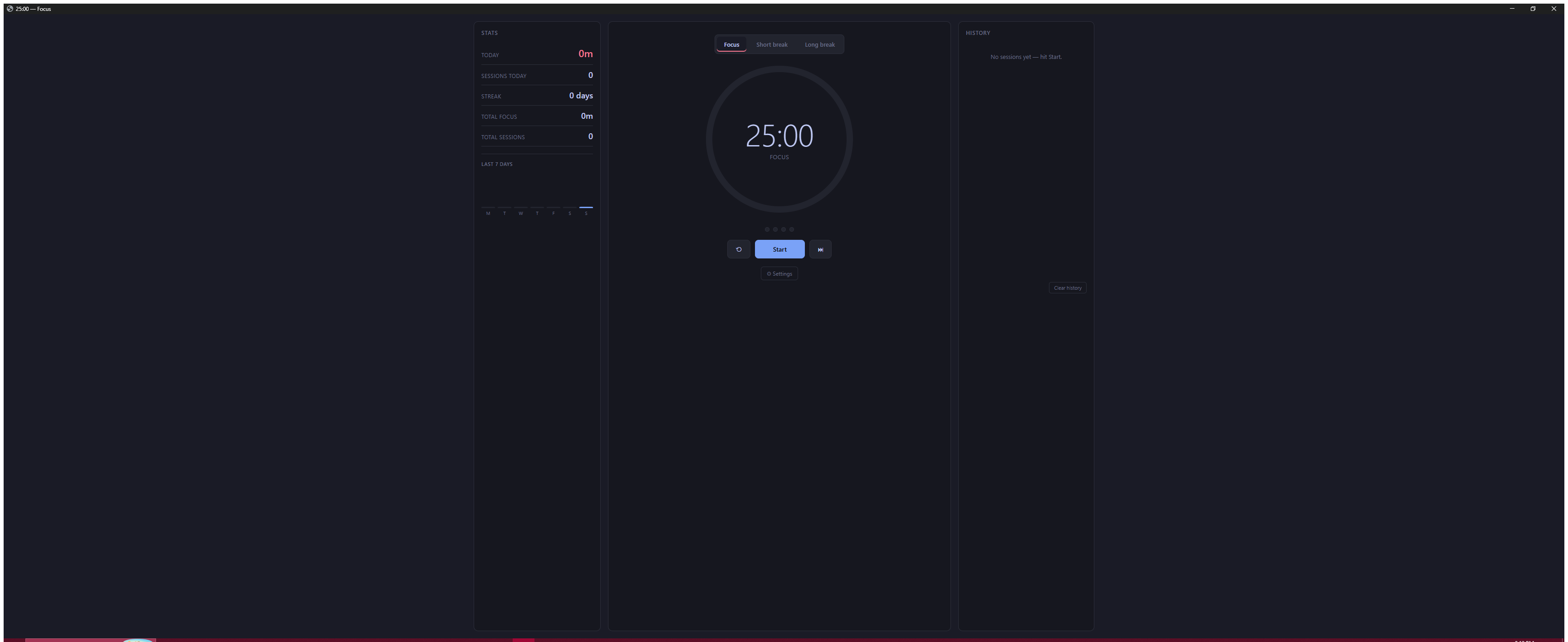
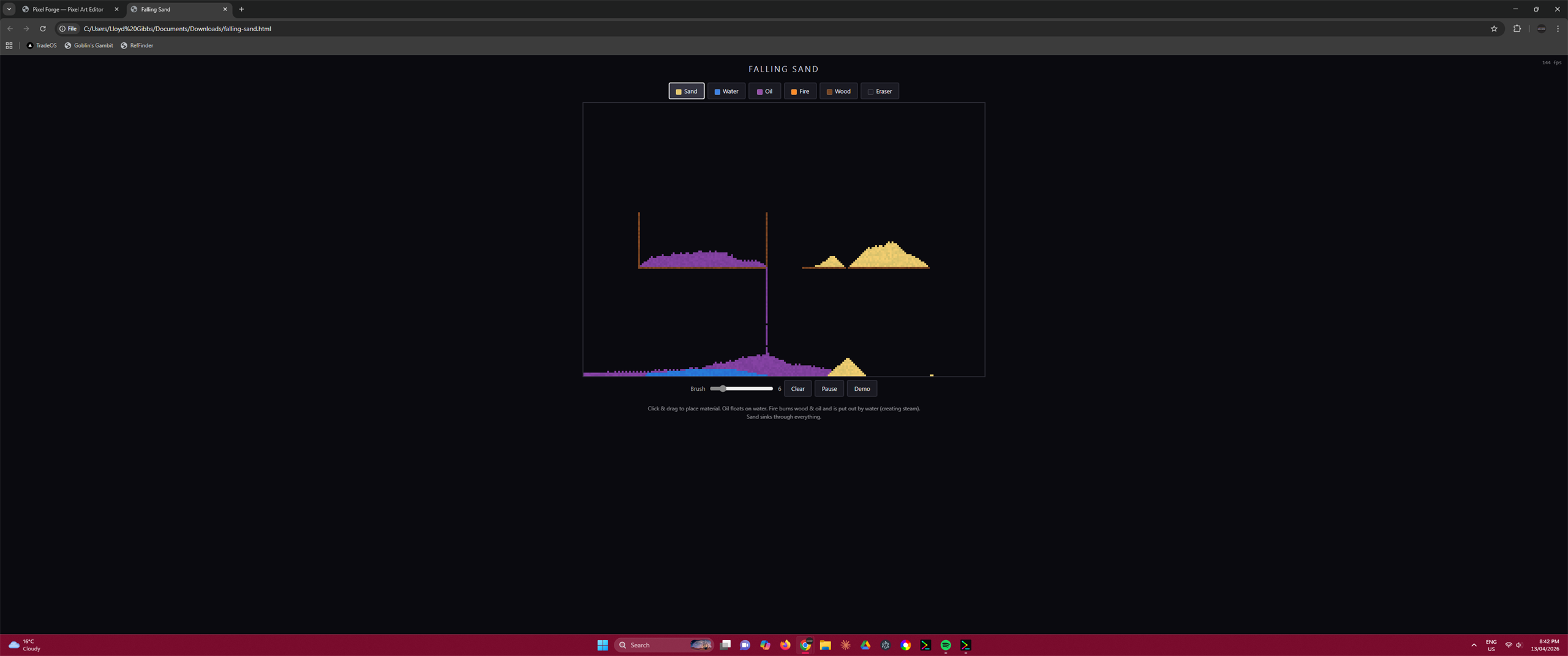
Same Prompt. Four Outputs.
Real side-by-side comparisons of vanilla Claude vs Godmode skills. Same prompt, same model, same environment — different execution protocols. The gap speaks for itself. Scores come from the skills' own dimensional scoring protocol; audit the raw JSON at /showcase/data/.
Don't trust a tool grading its own work? We stripped the labels and had a blind panel re-judge every pair — read the independent blind review. (Demos here were produced on Claude Opus 4.6; the blind panel judged on Opus 4.8 — the review's method note explains why the model labels differ.)
Want proof the paid gates actually block bad code? The gate demo runs the security scan and the correctness gate against a fixture with planted defects and against the same code fixed. No judge, no model in the loop, every gate envelope published verbatim and reproducible with one command.