Showcase
Same Prompt. Four Outputs.
We gave the same prompt to vanilla Claude and three Godmode tiers. The difference isn't subtle.
$ Make a falling sand simulation with water, fire, sand, wood, and oil that interact realistically.
The test: One prompt. No follow-up. No clarification. Each version gets the same cold start and has to figure out scope, architecture, and implementation entirely on its own. The metrics below are from real runs.
Results
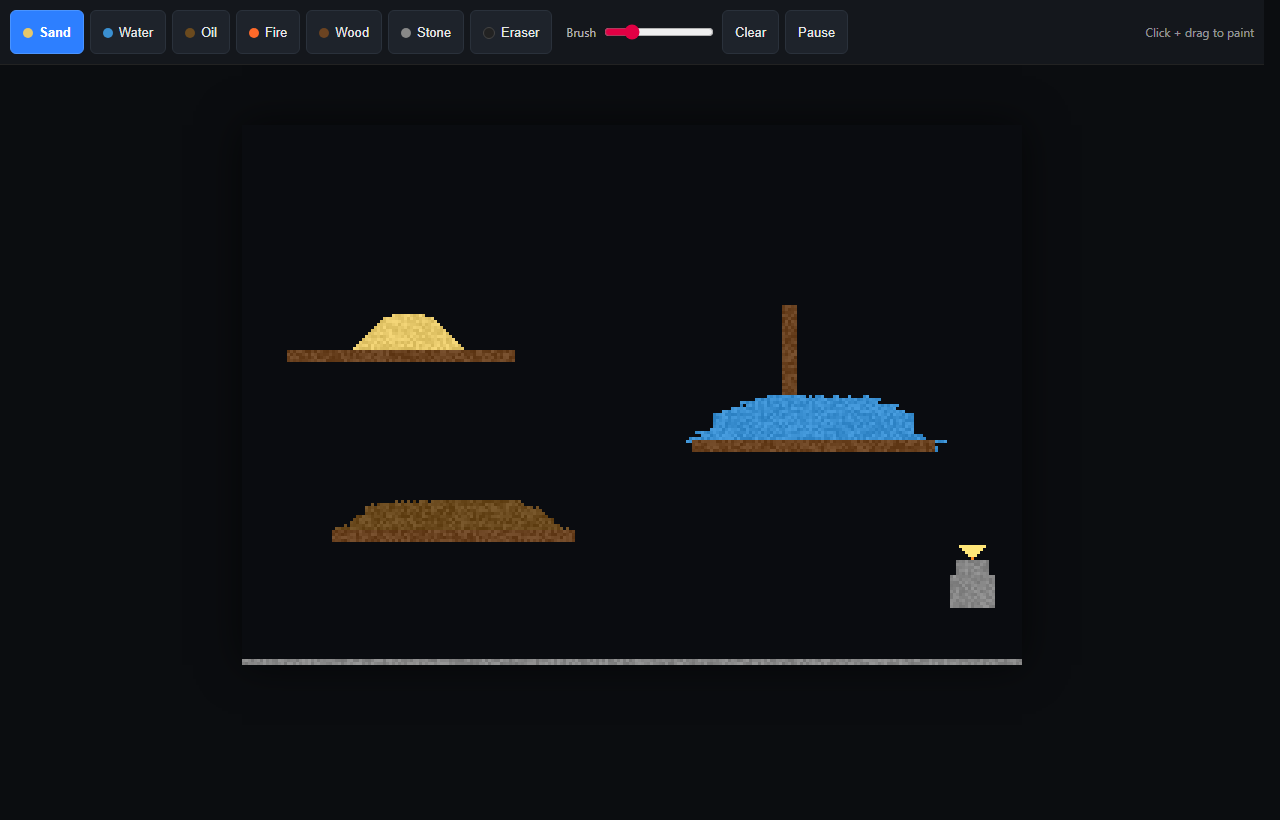
Total Tokens
12,000
5,200 in / 6,800 out
API Cost
$0.20
estimated
Time
3m 10s
wall clock
Files
1
created
Test Suite
0
tests written
Loops
0
no self-review
Quality Audit
Code Quality0.88
Testing0.10
Security0.85
Error Handling0.65
Completeness0.90
UX / Polish0.55
Issues Found
- highNo tests written — zero coverage of cell update logic, density rules, or fire spread
- highNot mobile responsive — no media queries, no touch event handlers, broken on phones and tablets
- mediumNo accessibility — no ARIA labels, no keyboard controls, color-only material indicators
- mediumFire updates can shoot through multiple cells per step (no per-frame visited mask), so flames disappear instantly into the ceiling
- mediumNo initial scene — launches to an empty canvas with no demonstration of the materials
- lowNo save/load, no scene presets, no FPS counter
- lowBrush range limited to 1–25; no fine-grained control or pressure sensitivity
Composite Score
0.66
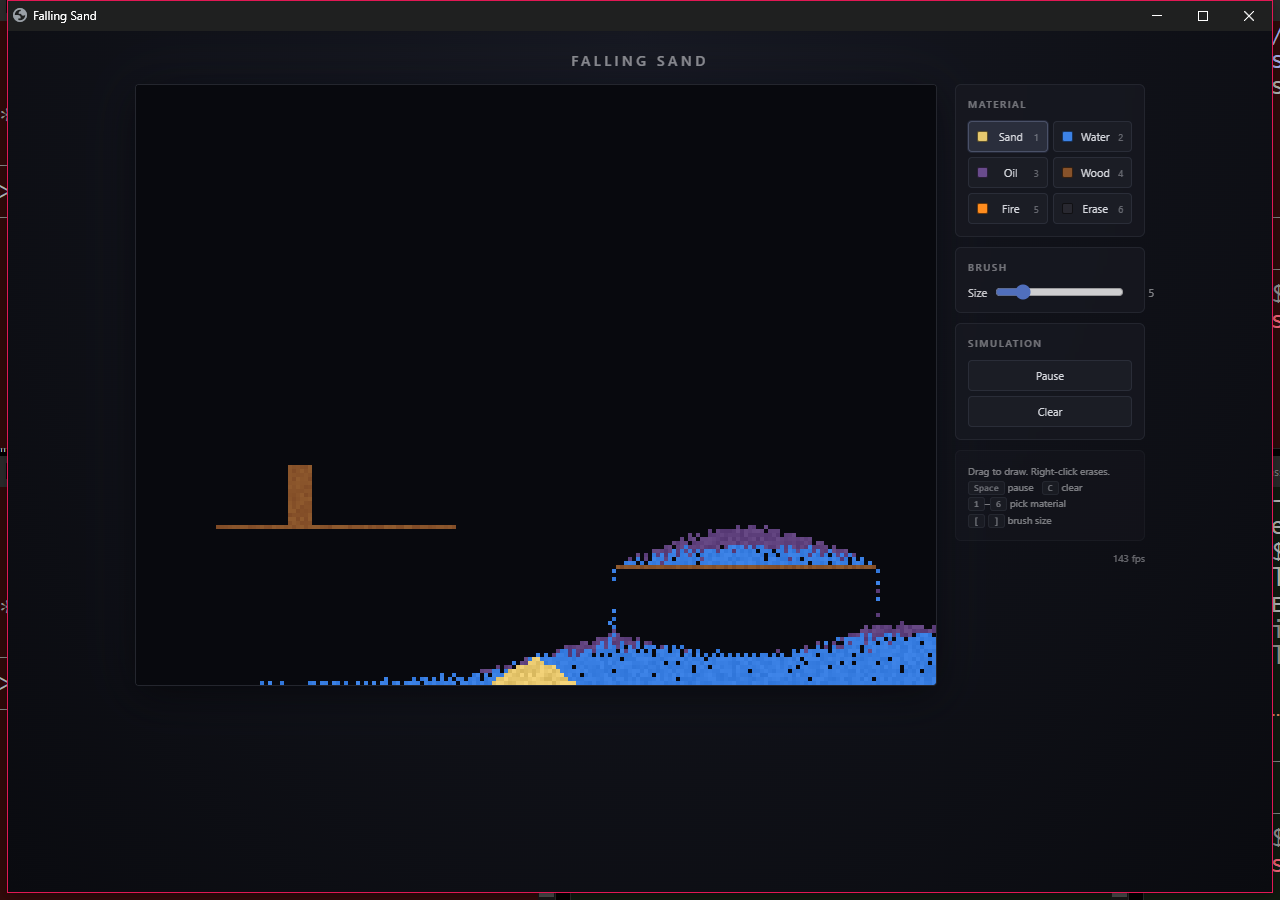
Total Tokens
46,000
35,000 in / 11,000 out
API Cost
$0.45
estimated
Time
8m 45s
wall clock
Files
1
created
Test Suite
0
tests written
Loops
0
single pass
Quality Audit
Code Quality0.92
Testing0.10
Security0.92
Error Handling0.82
Completeness0.96
UX / Polish0.92
Issues Found
- mediumNo automated tests — density rules, swap primitives, and fire propagation logic all untested despite being the heart of the sim
- lowFire propagation rates (1.2% wood, 28% oil) are magic numbers in updateFire without tuning comments explaining why
- lowOpening demo scene doesn't sustain fire indefinitely — the starter burns out in ~2s, leaving a mostly-static scene until the user interacts
- lowNo scene save/load or preset picker — clearing the canvas discards the user's work with no undo
- lowAt the 480px breakpoint the 3-column material grid can cramp longer labels like 'Erase'
Composite Score
0.75
Total Tokens
69,000
55,000 in / 14,000 out
API Cost
$0.63
estimated
Time
6m 20s
wall clock
Files
1
created
Test Suite
0
tests written
Loops
0
self-corrections
Quality Audit
Code Quality0.94
Testing0.15
Security0.92
Error Handling0.87
Completeness0.97
UX / Polish0.95
Issues Found
- fixedInitial demo scene had fire burning out in ~1s — extended fire lifetime to 120–200 frames so the starter burns visibly
- fixedWater horizontal spread was only 3 cells, looked sludgy — bumped to 5-cell lookahead for fluid feel
- fixedMobile CSS missing on first pass — added 768px + 480px breakpoints with 44px touch targets before shipping
- mediumNo automated tests for density swap primitives, buoyancy, or fire propagation — visual sim leaned on runtime/screenshot verification instead of unit tests
- lowFire propagation rates (1.2% wood, 25% oil) are magic numbers in updateFire without tuning comments
- lowNo scene save/load or additional presets beyond the single Demo button
- lowCanvas is fixed 220×150 grid — no resolution selector for users who want a bigger playfield
Composite Score
0.78
Head-to-Head
| Metric | Vanilla | Godmode | One-Shot |
|---|---|---|---|
| Total Tokens | 12,000 | 46,000 | 69,000 |
| API Cost | $0.20 | $0.45 | $0.63 |
| Time | 3m 10s | 8m 45s | 6m 20s |
| Files Created | 1 | 1 | 1 |
| Tests Written | 0 | 0 | 0 |
| Self-Corrections | 0 | 0 | 0 |
| Composite Score | 0.66 | 0.75 | 0.78 |
| Issues at Delivery | 7 | 5 | 4 |
Note: Higher token usage and cost for Godmode tiers reflects deeper execution — more context loaded, more tests written, more security checks, more verification passes. You're paying for quality, not verbosity.
See for yourself.
Same prompt. Same model. The only difference is the skill.
Stop settling for first-draft output.