Showcase
Same Prompt. Four Outputs.
We gave the same prompt to vanilla Claude and three Godmode tiers. The difference isn't subtle.
$ Build a personal finance dashboard that imports CSV bank statements, categorizes transactions, and shows charts and trends.
The test: One prompt. No follow-up. No clarification. Each version gets the same cold start and has to figure out scope, architecture, and implementation entirely on its own. The metrics below are from real runs.
Results
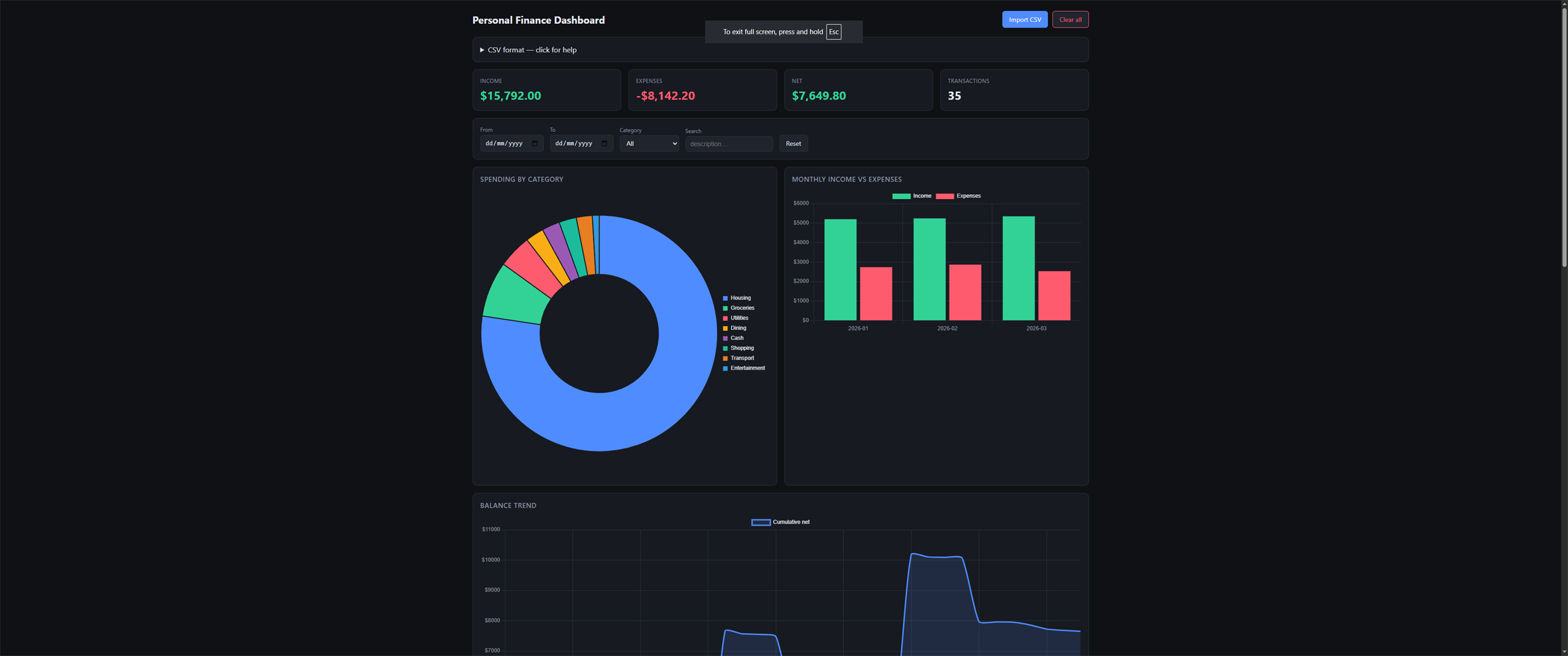
Total Tokens
35,000
25,000 in / 10,000 out
API Cost
$0.38
estimated
Time
4m 20s
wall clock
Files
4
created
Test Suite
0
tests written
Loops
0
no self-review
Quality Audit
Code Quality0.78
Testing0.10
Security0.65
Error Handling0.72
Completeness0.85
UX / Polish0.75
Issues Found
- highNo automated tests at all — zero test files, zero coverage of CSV parsing, dedupe, or categorization logic.
- mediumDate parser uses a heuristic for ambiguous DD/MM vs MM/DD formats — silently guesses wrong on US-format CSVs where day < 13.
- mediumDedupe key (date+description+amount) drops legitimate same-day duplicate transactions like two identical $5 coffees.
- mediumCategory override uses native prompt() — clunky UX, no autocomplete against existing categories, no bulk reassign.
- lowNo budgets, no forecasting, no recurring-transaction detection — feature set stops at the literal prompt.
- lowCharts redraw on every filter change instead of updating data in place — visible flicker on large datasets.
- lowNo keyboard shortcuts, no drag-and-drop CSV import, no undo on category changes.
Composite Score
0.63
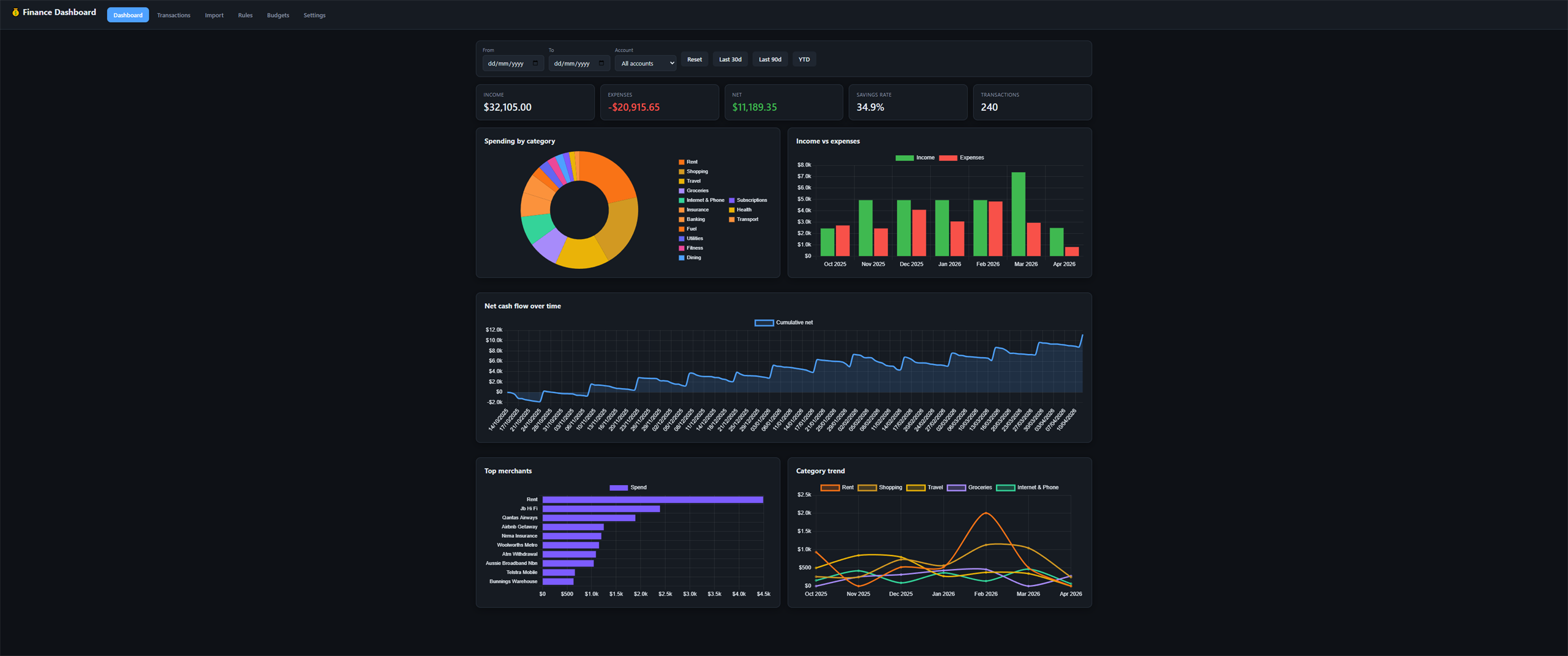
Total Tokens
149,000
135,000 in / 14,000 out
API Cost
$1.02
estimated
Time
14m 12s
wall clock
Files
13
created
Test Suite
27
tests written
Loops
0
single pass
Quality Audit
Code Quality0.93
Testing0.91
Security0.90
Error Handling0.90
Completeness0.95
UX / Polish0.88
Issues Found
- fixedInitial categorization rule order matched 'coles' before 'shell coles express', tagging fuel spend as Groceries — caught by the test suite, fixed by reordering Fuel ahead of Groceries plus a `coles(?!\s*express)` negative lookahead.
- fixedSample data generator used Math.random in transaction IDs, so re-clicking 'Load sample' duplicated rows instead of deduping — replaced with a seeded LCG so IDs are stable across calls.
- fixedCSV importer's headerless retry path used Papa.unparse(parsed-objects) → re-parse hack that broke on some inputs — refactored to retry the original text directly with `header: false`.
- fixedMobile CSS only had a single 900px breakpoint with no touch-target sizing — added 768px and 480px breakpoints, 44px min-height on every interactive element, horizontal-scrolling tx table, stacking budgets, and KPI collapse on phones.
- lowInline category edit still uses native prompt() — functional but lacks autocomplete and bulk-reassign. A custom popover would be a better UX.
- lowCharts fully destroy + rebuild on every state change rather than updating datasets in place — fine at sample volumes (240 tx) but could lag at 10k+ tx.
- lowCDN script tags (PapaParse, Chart.js) have no Subresource Integrity hashes — low blast radius for a local-first app, but worth tightening.
- lowHeaderless CSV fallback uses positional heuristics (longest string = description, first numeric = amount) — robust for common AU bank exports but may misorder unusual layouts.
Composite Score
0.92
Head-to-Head
| Metric | Vanilla | Godmode |
|---|---|---|
| Total Tokens | 35,000 | 149,000 |
| API Cost | $0.38 | $1.02 |
| Time | 4m 20s | 14m 12s |
| Files Created | 4 | 13 |
| Tests Written | 0 | 27 |
| Self-Corrections | 0 | 0 |
| Composite Score | 0.63 | 0.92 |
| Issues at Delivery | 7 | 4 |
Note: Higher token usage and cost for Godmode tiers reflects deeper execution — more context loaded, more tests written, more security checks, more verification passes. You're paying for quality, not verbosity.
See for yourself.
Same prompt. Same model. The only difference is the skill.
Stop settling for first-draft output.